
Экономика GenAI: TCO vs цена за токен и стоимость «мышления» — почему дешёвый токен не даёт дешёвый результат
Цена за токен кажется простой метрикой. Прайсы с рублями за 1 000 токенов создают ощущение прозрачности. Но они скрывают главное — полную стоимость владения и цену «мышления».
Моя позиция проста: при равном качестве выигрывает не самая «умная» модель, а та, где предсказуема стоимость результата и контролируемы риски. Это и есть реальная экономика GenAI.
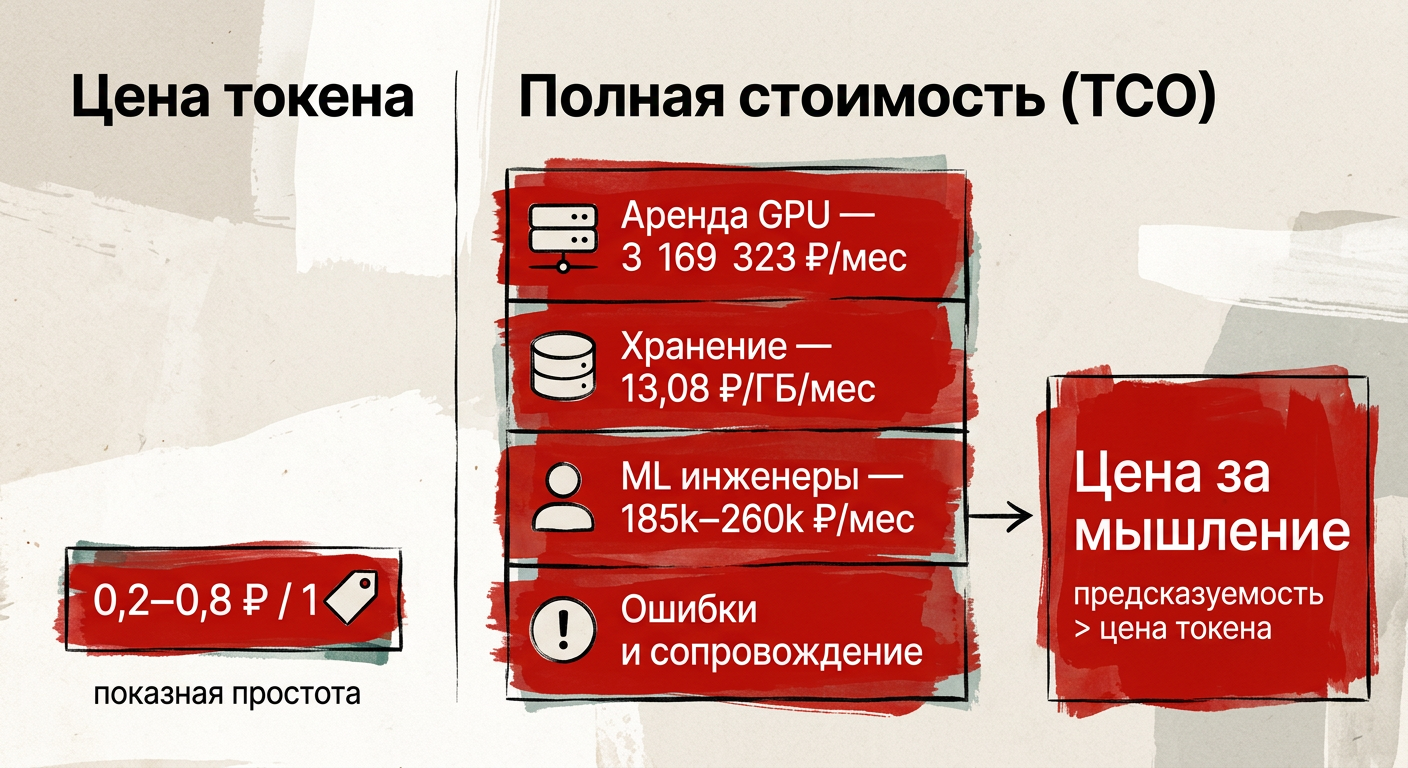
Показательный пример: при 1 млн запросов в месяц YandexGPT Lite стоит около 300 000 ₽, Pro — около 1 200 000 ₽. Но аренда конфигурации с 8 A100 — около 3 169 323 ₽ в месяц. Эти расходы быстро перекрывают разницу в цене токена.
Отсюда ключевой вопрос: как перевести цену токена в цену результата и выбрать между managed API и self‑hosting без ошибок в бюджете.
Почему цена токена вводит в заблуждение
Выбор LLM часто сводят к цене за 1 000 токенов. Сравнения «0,2 ₽ vs 0,8 ₽» кажутся достаточными для решения.
Но токены отражают только прямые вычисления. Реальная стоимость включает аренду GPU, хранение, зарплаты и сопровождение. Например: аренда g2.8 с 8 A100 — около 3 169 323 ₽ в месяц, ML Engineer — ≈185 000 ₽ (в Москве ≈260 000 ₽).
При росте нагрузки эти статьи перекрывают разницу в цене токена.
Если опираться только на прайс токенов, легко выбрать решение с высокой суммарной стоимостью и непредсказуемыми рисками. Поэтому главный вопрос — как считать цену результата, а не цену токена.
Как считать реальную стоимость LLM
Как это работает
Токен — это единица вычислений, а не итоговая стоимость. LLM работают как инфраструктура: к цене токена добавляются железо, хранение и люди.
Каждый запрос тянет за собой операции: развертывание, мониторинг, дообучение, хранение эмбеддингов, повторные вызовы. Эти расходы растут вместе системой, а не только с числом токенов.
Почему цена токена искажает картину
YandexGPT Lite стоит 0,2 ₽ за 1 000 токенов, Pro — 0,8 ₽. Разница кажется четырёхкратной.
Но при 1 млн запросов это 300 000 ₽ против 1 200 000 ₽. Дальше включается инфраструктура: аренда g2.8 с 8 A100 — около 3 169 323 ₽ в месяц. Хранение — 13,08 ₽ за ГБ. Эти расходы доминируют.
Добавьте людей: ML Engineer — ≈185 000 ₽, в Москве ≈260 000 ₽. Senior — 280–350 000 ₽, Lead — 360–450 000 ₽. Без них система не работает.
Отдельно — риск ошибок. Неверные ответы ведут к повторным вызовам, исправлениям и потерям.
Даже скидки не меняют базу. DeepSeek давал 75% скидку и снизил стоимость повторных запросов до 10%. Это влияет на счёт, но не убирает постоянные расходы.
Пример расчёта «цены за результат»
Возьмём сценарий: 1 млн запросов в месяц.
Токены (API):
YandexGPT Lite ≈ 300 000 ₽
Инфраструктура (если self‑hosting или гибрид):
GPU (g2.8, 8×A100) ≈ 3 169 323 ₽
Хранение: зависит от объёма, например 13,08 ₽/ГБ
Персонал:
2 ML Engineer: ≈ 370 000–520 000 ₽
Операционные потери:
Повторные вызовы и ошибки — переменная статья
Формула: Цена результата = (токены + инфраструктура + персонал + ошибки) / число полезных ответов
Вывод из примера: доля токенов в общей стоимости может быть меньшей частью. Основную нагрузку дают инфраструктура и команда.
К чему это приводит
Сравнение по токенам перестаёт работать на масштабе. Разница в 5–15% по качеству моделей не всегда оправдывает рост расходов.
Бизнес смещает фокус: важна предсказуемая стоимость результата.
Отсюда и новая логика рынка: «рынку нужно будет не «лучшее мышление», а «достаточно хорошее мышление с предсказуемой экономикой».
Что теперь важно
Цена за токен — только сигнал. Решение принимают по TCO и цене результата.
Выбор LLM становится задачей финансовой инженерии, где считают не модель, а экономику её использования.

Типичные ошибки при выборе LLM
Когда прайс‑лист решает вместо вас
Вы выбираете YandexGPT Lite из‑за 0,2 ₽ за 1 000 токенов.
Нагрузка растёт. Появляются расходы на хранение, донастройку и поддержку.
Экономия исчезает. Бюджет уходит в инфраструктуру и людей.
Когда скидка ломает расчёты
Поставщик даёт скидку 75%.
Пилот проходит успешно. Затем растут повторные вызовы и мониторинг.
Фактические расходы оказываются выше ожидаемых.
Когда «лучшее» дороже результата
Выбирают модель с +10% качества.
Но интеграция и сопровождение съедают бюджет.
Проект тормозит из‑за стоимости и неопределённости.
Общий вывод: цена модели и цена результата — разные вещи.
Вариант | Цена токена (₽ / 1k входящих / 1k исходящих) | Стоимость при 1 млн запросов/мес (₽) | Ключевые инфраструктурные / кадровые показатели |
|---|---|---|---|
YandexGPT Lite | 0,2 / 0,2 | 300 000 | managed API |
YandexGPT Pro 5.1 | 0,8 / 0,8 | 1 200 000 | managed API |
DeepSeek V3.2 | 0,5 / 0,8 | 900 000 | DeepSeek: скидка 75% на V4‑Pro; повторные запросы снижены до 10% |
Self‑hosting (g2.8, 8×A100) | — | — | Аренда 8×A100 (g2.8): 3 169 323 ₽/мес; хранение в DataSphere: 13,08 ₽/ГБ/мес; ML Engineer: 185 000 ₽/мес (Москва ≈260 000 ₽); Senior 280–350 000 ₽; Lead 360–450 000 ₽ |
Как менять подход к выбору модели
Токен — это ориентир, не бюджет.
Практический сдвиг такой:
считать цену за результат, а не за 1 000 токенов
закладывать инфраструктуру и команду с первого дня
учитывать стоимость ошибок и повторных вызов
сравнивать варианты по предсказуемости расходов
Это меняет решения. Вместо «дешевле в прайсе» выбирают «стабильнее в эксплуатации».
Именно поэтому бизнес начинает считать не лучшую модель, а стоимость за результат.
Что делать на практике
Проблема не в моделях, а в метрике выбора. Цена токена даёт иллюзию контроля и ломается на масштабе.
Рабочий подход:
Собрать TCO: токены, инфраструктура, хранение, команда.
Посчитать цену за результат по формуле.
Проверить чувствительность: как меняется стоимость при росте нагрузки и ошибок.
Сравнить managed API и self‑hosting по предсказуемости, а не только по цене.
Почему это работает. Постоянные расходы доминируют над скидками и прайсом токенов. Их учёт делает бюджет управляемым.
На практике это реализуют платформы, которые объединяют хранение, RAG и работу модели внутри инфраструктуры компании. Такой подход снижает разброс затрат и упрощает расчёт TCO.
Вывод: экономика GenAI: TCO vs цена за токен и стоимость «мышления» — это про контроль результата, а не про минимальную цену в прайсе.









