
Влияние data‑платформы и lakehouse‑архитектуры на ROI AI‑проектов: когда инфраструктура съедает прибыль
Модель может быть точной, а проект — убыточным. Причина проста: экономику определяет не алгоритм, а data‑платформа. Lakehouse и MLOps снижают стоимость хранения и масштабирования в разы. Без них расходы растут быстрее, чем польза от точности.
Это видно на практике. В проектах внедрение lakehouse сокращало стоимость хранения в 7 раз, а оптимизация конвейеров — затраты на масштабирование в 13–15 раз. Такие изменения переворачивают экономику.
Проблема проявляется при переходе от пилота к продакшену. Ограничения по памяти на edge‑устройствах, сетевой трафик и требования к задержке инференса быстро съедают выигрыш от модели. В результате даже точные решения не окупаются.
Дальше — где именно возникают потери и какие элементы платформы влияют на ROI. Также разберём критерии зрелости data‑платформы, по которым принимают решение: масштабировать AI или сначала перестроить архитектуру.
Почему точная модель не даёт ROI
Кажется, что достаточно натренировать точную модель. Руководители смотрят на AUC и F1, оценивают пилот и ожидают рост ROI. В центре внимания — алгоритмы, а не платформа.
На практике всё решает архитектура данных. Без lakehouse и MLOps хранение и масштабирование съедают эффект от точности. В проектах lakehouse снижал стоимость хранения в 7 раз, а оптимизация конвейеров — расходы на масштабирование в 13–15 раз.
Добавьте ограничения: память на edge, сетевой трафик, задержка инференса. Даже точная модель становится непрактичной.
В итоге команды продолжают улучшать модель, пока инфраструктура разрушает экономику. Пилоты превращаются в дорогие интеграции, бюджеты растут, доверие падает. Ключевой вопрос: где теряются деньги и какие решения это исправляют.
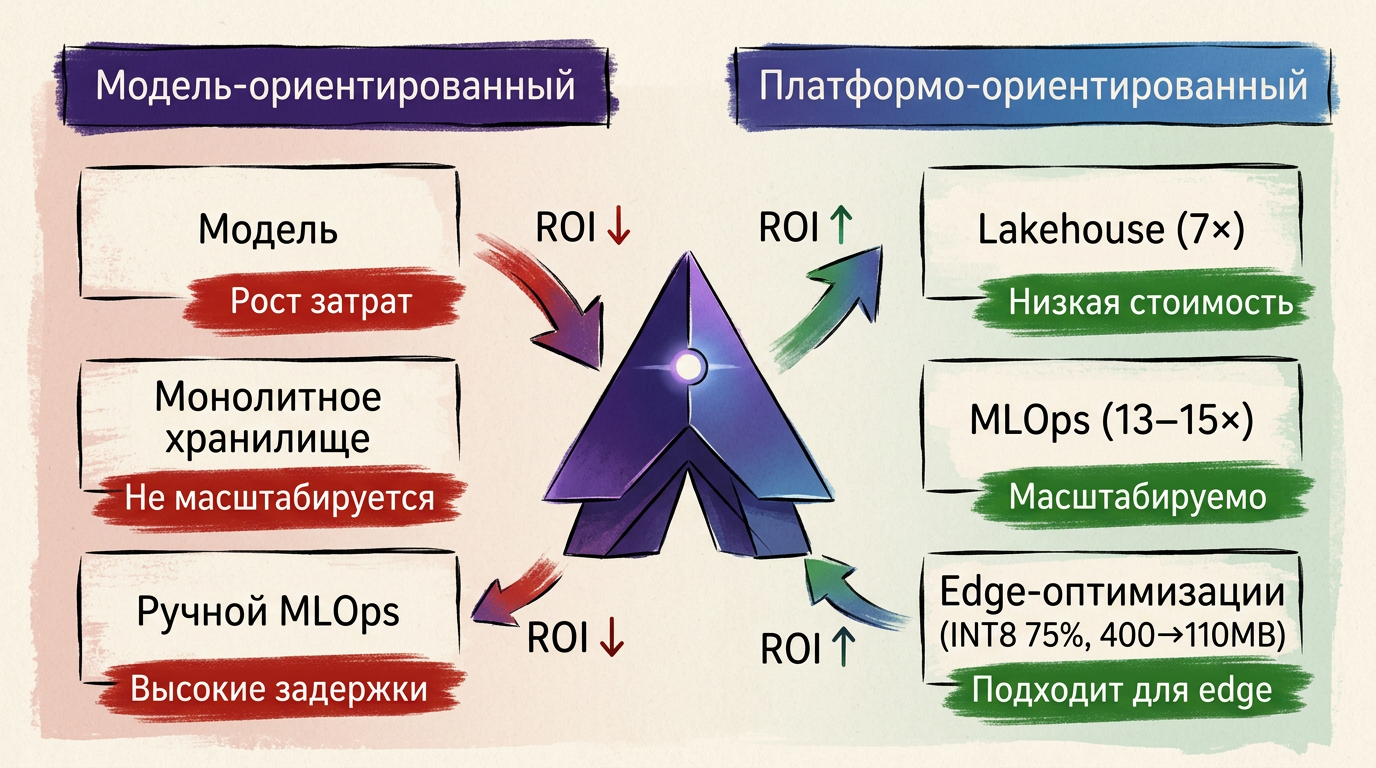
Как инфраструктура формирует экономику AI
Как устроена экономика: данные, конвейеры, инференс
Инфраструктура — это источник расходов. Данные собирают, хранят и обогащают. Затем они проходят через конвейеры и попадают в модель. После запуска добавляются инференс и логирование.
Каждый этап стоит денег: хранение, трансформации, пересчёт фичей, вычисления. Пока объёмы малы, это незаметно. При росте пользователей расходы начинают доминировать.
Что происходит при масштабировании
Пилот с тысячами записей дешёв. При сотнях тысяч пользователей резко растут хранение инференс. Если платформа не оптимизирована, улучшения модели только увеличивают счета.
Почему lakehouse и MLOps меняют результат
Lakehouse убирает дубли избыточное хранение. MLOps автоматизирует конвейеры и снижает ручной труд. В реальных внедрениях это давало кратный эффект: хранение дешевле в 7 раз, масштабирование — в 13–15 раз.
Похожие эффекты видны на уровне бизнеса. Например, VK Tech показала рост выручки 38% при среднем росте рынка 24%. Такие результаты возможны, когда платформа масштабируется без взрывного роста затрат.
Ограничения железа и edge
Аппаратные рамки задают пределы. В федеративных сценариях доступно около 256 МБ памяти. Модель сжимают до ~65 МБ без потери точности. INT8 уменьшает размер на 75%. Динамическая загрузка слоёв снижает потребление с ~400 МБ до ~110 МБ.
Это не оптимизации «на потом». Без них продакшен не масштабируется.
К чему это приводит
Без зрелой платформы рост данных делает продукт убыточным. Метрики модели растут, а вместе с ними — счета за хранение инференс. Даже при точности выше 90% бизнес‑эффект может исчезнуть.
Фокус смещается: считать нужно не только метрики модели, но и стоимость полного цикла данных.
Где именно теряются деньги
Пилот точен, но хранение выходит из‑под контроля
Пилот показывает хорошие метрики. Команда начинает сохранять больше логов, версий и фичей.
При росте данных конвейер не справляется. Появляются дубли, разрозненные хранилища, тяжёлые ETL. Хранение и трансформации становятся главным расходом.
Через несколько месяцев счета превышают бюджет. Рост ценности от модели замедляется.
Что делать: навести порядок в хранении — убрать дубли, перейти к единой схеме и контролировать стоимость операций.
Добавили данные — сломали систему
Подключают новые источники без общей модели данных. Появляются копии и несовместимые схемы.
Пайплайны начинают падать. Инференс замедляется. Данные не обрабатываются вовремя.
Команда тратит время на восстановление, а не на развитие.
Что делать: управлять жизненным циклом данных — дедупликация, единые схемы, контроль качества пайплайнов.
Edge: модель работает, экономика — нет
Модель запускают на устройстве с ограничениями. Требование — задержка <100 мс.
Метрики держатся, но трафик и частые синхронизации растут. Устройство перегружается, расходы на связь увеличиваются.
Сервис становится нестабильным.
Что делать: оптимизировать не только модель, но и обмен данными — снижать частоту синхронизаций и объём трафика.
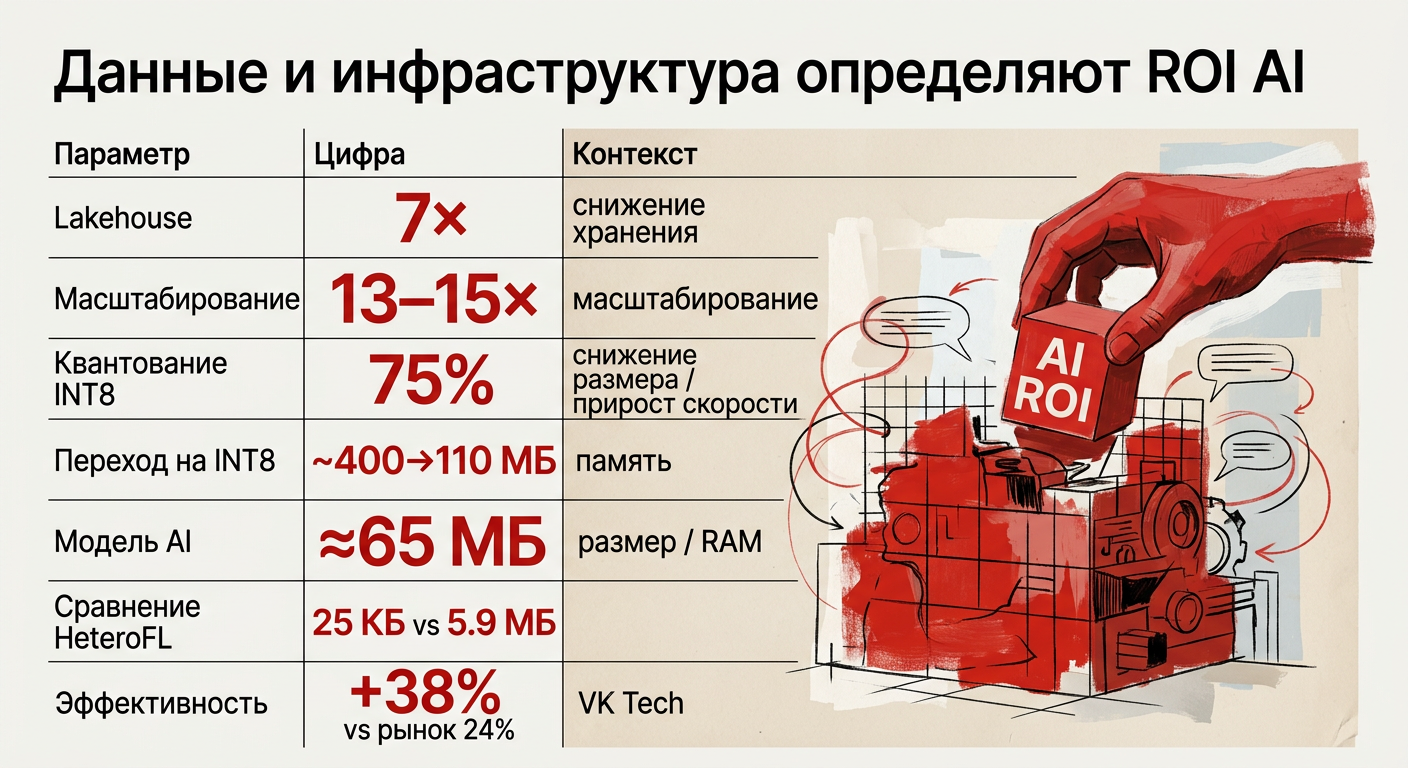
Параметр | Цифра / диапазон | Источник / контекст |
|---|---|---|
Снижение стоимости хранения при внедрении lakehouse | 7× | Внедрение lakehouse снизило стоимость хранения данных в 7 раз |
Снижение затрат на масштабирование инфраструктуры | 13–15× | Оптимизация конвейеров инфраструктуры уменьшала затраты на масштабирование в 13–15 раз |
Уменьшение размера при INT8‑квантовании | 75% | INT8‑квантование уменьшает размер данных на 75% |
Снижение потребления памяти при динамической загрузке слоёв | ~400 МБ → ~110 МБ | Динамическая загрузка слоёв снижает потребление памяти с ~400 МБ до ~110 МБ |
Размер сжатой модели в продакшене | ≈65 МБ | Модель была сжата до примерно 65 МБ без значимой потери точности |
HeteroFL — размер подсетей vs полная модель | 25 КБ vs 5.9 МБ | Подсети HeteroFL могут уменьшаться до 25 КБ против полной модели 5.9 МБ |
Рост выручки VK Tech (2025) | +38% (рынок +24%) | Выручка VK Tech в 2025 году выросла на 38% при среднем росте рынка 24% |
Почему платформа даёт больший эффект
Результат даёт не модель сама по себе, а то, как она встроена в платформу. Экономика масштабируется через хранение, конвейеры инференс.
Когда платформа зрелая, снижается полная стоимость владения: меньше дублирования данных, стабильные пайплайны, предсказуемые расходы. Дополнительно падают задержки инференса и нагрузка на устройства.
Если этого нет, происходит обратное. Команда улучшает гиперпараметры, а расходы на хранение, вычисления и поддержку растут быстрее пользы. Пилоты с хорошими метриками останавливаются из‑за стоимости эксплуатации.
Отсюда практический приоритет: сначала проверяют хранение, MLOps инференс‑оптимизации. Только после этого масштабируют модель.
Проблема в том, что команды смотрят на метрики модели игнорируют стоимость платформы. При масштабировании расходы на хранение, конвейеры инференс растут быстрее, чем эффект от точности.
Решение — строить зрелую data‑платформу. Lakehouse снижает избыточность данных, MLOps стабилизирует конвейеры и автоматизирует цикл. В проектах это давало кратный эффект: хранение дешевле в 7 раз, масштабирование — в 13–15 раз. Для edge критичны оптимизации: INT8 (−75% размера) и динамическая загрузка (~400→110 МБ).
Эта логика подтверждается практикой. Рост выручки VK Tech на 38% при среднем рынке 24% показывает, что масштабирование возможно без пропорционального роста затрат.
Платформенные решения, такие как АСПЕКТ, работают по тому же принципу: обрабатывают документы, аудио и видео внутри инфраструктуры компании и превращают их в управляемый поток данных. Это снижает ручной труд и делает расходы предсказуемыми.
Вывод однозначный: влияние data‑платформы и lakehouse‑архитектуры на ROI AI‑проектов решающее — сначала платформа, потом масштабирование моделей.









