
Успех AI‑проекта всё чаще измеряют не числом инженеров, а счётом за вычисления. Команда из четырёх человек может генерировать расходы уровня крупного отдела: например, Swan AI заплатила $113 000 за токены за месяц. Это не исключение, а новая норма — экономика токенов в ИИ и рост инфраструктурных затрат переворачивают привычную логику юнит‑экономики.
Моя позиция проста: вычисления становятся новой зарплатой. Значит, решения о росте, найме и цене продукта нужно принимать через контроль вычислительных расходов, а не через увеличение команды.
Это меняет сам рынок. Когда Google выделяет $750 млн на продвижение AI‑агентов и раздаёт кредиты на внедрение, конкуренция идёт не только за людей, но и за доступ к вычислениям. Для фаундеров и продуктовых команд ключевой вопрос теперь другой: не «сколько людей нанять», а «сколько токенов мы можем позволить себе до выхода в прибыль».
Главный конфликт здесь — разрыв между идеей «маленькая команда строит большой продукт» и реальной стоимостью эксплуатации моделей. Дальше разберём, как считать новую юнит‑экономику и где возникают ограничения роста.
Почему команда больше не главный фактор роста
Кажется, что масштаб AI‑проекта зависит от команды. Больше инженеров — больше функций и быстрее рост. Это привычная логика для инвесторов и менеджеров.
Но структура расходов сместилась. Теперь основная нагрузка — вычисления и облако. Даже небольшая команда может генерировать огромные счета: до $100 000 на вычисления у отдельных сотрудников в период активных экспериментов.
Проблема в том, что старые метрики этого не учитывают. Продукт выглядит прибыльным, если считать только зарплаты. Но после добавления стоимости токенов инфраструктуры экономика может стать убыточной.
Отсюда возникает ключевой вопрос: какие показатели считать и где ставить ограничения. Ответ лежит в пересборке юнит‑экономики вокруг вычислений.
Как устроена новая экономика вычислений
Как считается расход
В AI расходы растут вместе с использованием. Каждый запрос к модели превращается в токены. Дальше всё просто: токены умножаются на цену и время выполнения.
Базовая формула: расход = (токены на запрос × цена за токен) × количество запросов.
Пример. Если один запрос стоит $0,02, а пользователь делает 50 запросов, то: $0,02 × 50 = $1 на пользователя. При 10 000 пользователей это уже $10 000 в месяц только на инференс.
Почему расходы растут быстрее ожиданий
Компании зависят от мощных моделей и агентных сценариев. Это увеличивает потребление токенов.
Пример Swan AI показывает сдвиг: команда из четырёх человек потратила $113 000 за месяц. Малый штат больше не означает низкие расходы.
Параллельно крупные игроки усиливают тренд. Google выделяет $750 млн на AI‑агентов и покрывает PoC, инженеров и кредиты. Это упрощает запуск, но не снижает постоянные расходы.
Что ломается в юнит‑экономике
Расходы переезжают из зарплат в инфраструктуру. Компании вроде Lovable с темпом $400 млн ARR уже зависят от стоимости вычислений при расчёте маржи.
Ошибка — пытаться решить проблему наймом. Больше людей ускоряет эксперименты, а значит увеличивает потребление токенов.
В итоге продукт может выглядеть прибыльным, пока не учтён инференс. После этого экономика часто рушится.
Ключевой вывод
Вычисления — это новая зарплата. Ограничивать нужно не людей, а стоимость операций. Дальше это нужно перевести в конкретные метрики и лимиты.
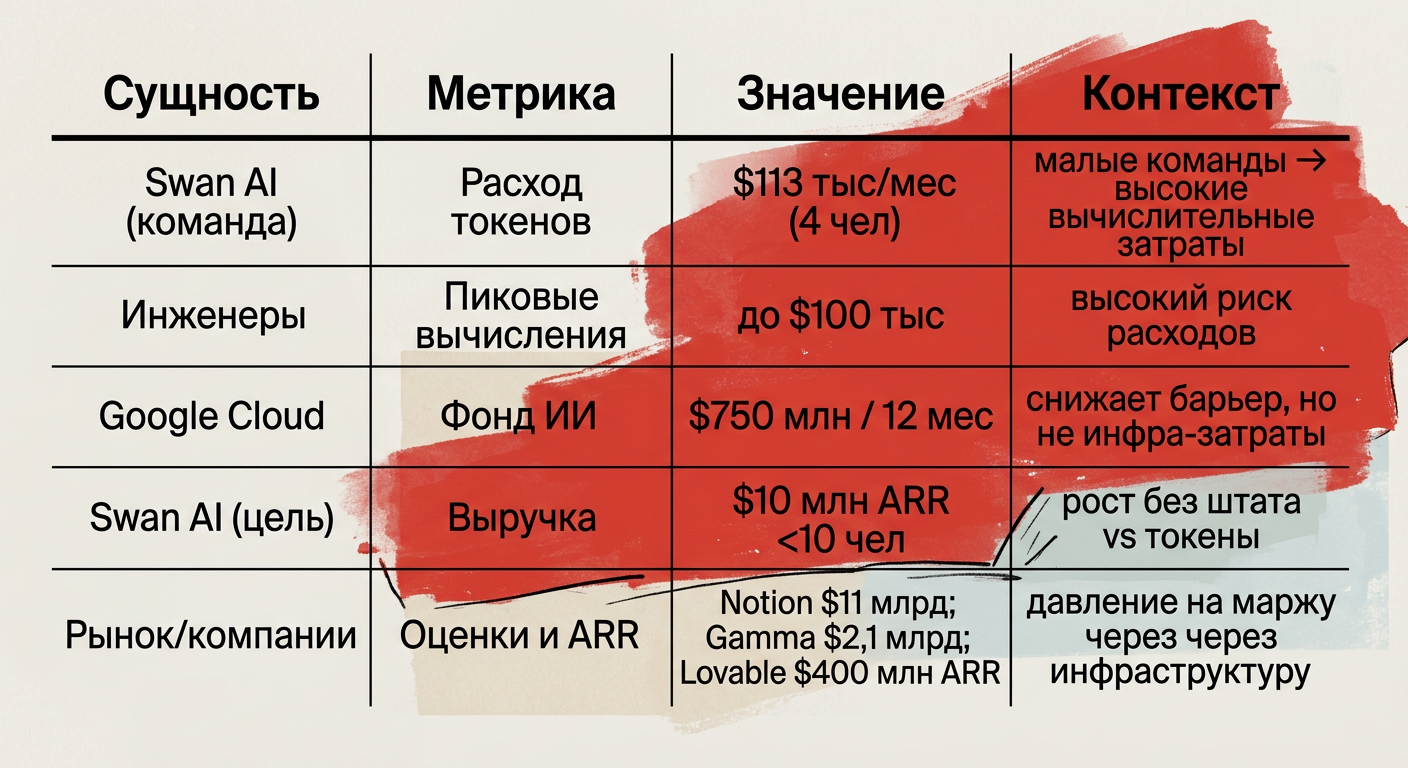
Где расходы выходят из-под контроля
Рост продукта ускоряет рост затрат
Вы запускаете новую функцию и получаете больше запросов.
Но вместе с этим растёт инференс. Расходы увеличиваются быстрее, чем вы успеваете оптимизировать систему.
Последствие: выручка растёт, но маржа падает из‑за стоимости токенов.
Намёк: считайте экономику на уровне запроса, а не команды.
Найм увеличивает счёт за вычисления
Вы нанимаете инженеров, чтобы ускорить разработку.
Они запускают больше экспериментов. Каждый эксперимент — это дополнительные вычисления. В отдельных случаях траты доходят до $100 000 на человека.
Последствие: R&D начинает съедать маржу.
Намёк: оценивайте найм через влияние на инференс‑расходы.
Кредиты скрывают реальную экономику
Вы используете облачные кредиты для запуска.
Программы вроде $750 млн от Google покрывают пилоты и внедрение. Но после окончания кредитов все расходы возвращаются.
Последствие: модель кажется дешёвой только на старте.
Намёк: считайте экономику без субсидий.
Entity | Metric | Value | Context / relevance to thesis |
|---|---|---|---|
Swan AI (team) | Token spend (team) | $113,000 / month (team of 4) | Shows small teams can incur large token costs, shifting economics from headcount to compute |
Individual engineers | Peak compute spend | Up to $100,000 | Experiments can create very high per-person compute bills, amplifying operational risk |
Google (Cloud program) | Fund for AI agents and partners | $750,000,000 over 12 months | Credits lower PoC barriers but do not eliminate long‑term infra costs |
Swan AI (goal) | Target revenue with small team | $10,000,000 ARR with <10 people | Ambition to scale revenue without large headcount collides with token/infrastructure expenses |
Lovable | Revenue run rate | $400,000,000 ARR (tempo) | Example of scale where infrastructure economics materially affect margins |
Market signals (valuations/forecasts) | Valuations / revenue forecasts | Notion ≈ $11B; Gamma $2.1B; Medvi $1.8B (forecast) | High valuations and forecasts indicate capital flow into AI, increasing emphasis on infrastructure economics |
Как это меняет управленческие решения
Главный сдвиг: вы управляете не людьми, а вычислениями.
Это влияет на три вещи:
Найм. Он увеличивает скорость экспериментов и расходы.
Ценообразование. Цена должна покрывать стоимость запроса.
Планирование. Инференс становится постоянным OPEX.
Практический вывод: вводите лимиты на токены и считайте cost per request как базовую метрику.
Второй вывод: проверяйте экономику без внешних кредитов. Только так видно реальную маржу.
Старая логика больше не работает: маленькая команда не гарантирует низкие расходы.
Решение — считать вычисления как постоянную статью затрат и управлять ими напрямую. Это значит: ввести дашборд с метриками токенов, установить лимиты на инференс и связать стоимость запроса с маржой продукта.
Это необходимо, потому что именно вычисления масштабируют расходы и риск.
Практический шаг: зафиксируйте cost/request, задайте потолок на пользователя и отслеживайте общий счёт за инференс в реальном времени. Без этого рост будет съедать прибыль.
Платформы вроде АСПЕКТ помогают внедрить такой контроль: они превращают AI‑слой в управляемый процесс внутри инфраструктуры и позволяют автоматизировать обработку данных без потери контроля над затратами.









