
Обучение AI-агентов на ошибках через память и reasoning frameworks: польза и скрытые риски
Память агентов меняет поведение, а не просто хранит опыт. Обучение AI-агентов на ошибках через память и reasoning frameworks сокращает число шагов и повышает успешность задач на бенчмарках WebArena и SWE-Bench-Verified с Gemini‑2.5-Flash. Но тот же механизм может незаметно смещать стратегию.
Я рассматриваю память как управляющий слой. Он влияет на выбор действий и требует такого же контроля, как код. Выигрыш в эффективности есть, но вместе с ним приходит обратная связь, которую нужно отслеживать.
Практическое следствие — замкнутый цикл: память направляет исследование, а исследование дополняет память. В продакшене это приводит к накоплению процедурных правил и «предупреждающих уроков». Со временем они формируют устойчивые, но не всегда корректные стратегии.
Для инженеров и продакт‑команд это означает одно: без строгой валидации и наблюдаемости память становится источником дрейфа. Дальше разберём цикл память → действие → самооценка → обновление памяти и точки риска.
Почему память не равна улучшению стратегии
Идея выглядит простой: память накапливает опыт, агент делает меньше шагов и решает задачи лучше. Кажется, что самооценка через LLM отфильтрует ошибки.
Но память — это не журнал. Она управляет выбором действий. Практика ReasoningBank и MaTS показывает: растёт успешность и падает число шагов, но одновременно формируются устойчивые правила поведения.
Проблема в том, что в память попадают и ошибки. Например:
агент начинает избегать валидных путей из‑за «предупреждения» из прошлого эпизода
закрепляется неверная причинно‑следственная связь, и агент повторяет её в новых задачах
Если цикл обновления не валидирован, такие правила закрепляются. В результате память усиливает не только удачные эвристики, но и ошибки.
Отсюда конфликт: рост эффективности сопровождается риском смещения поведения в продакшене. Значит, память нужно тестировать и наблюдать как часть системы.
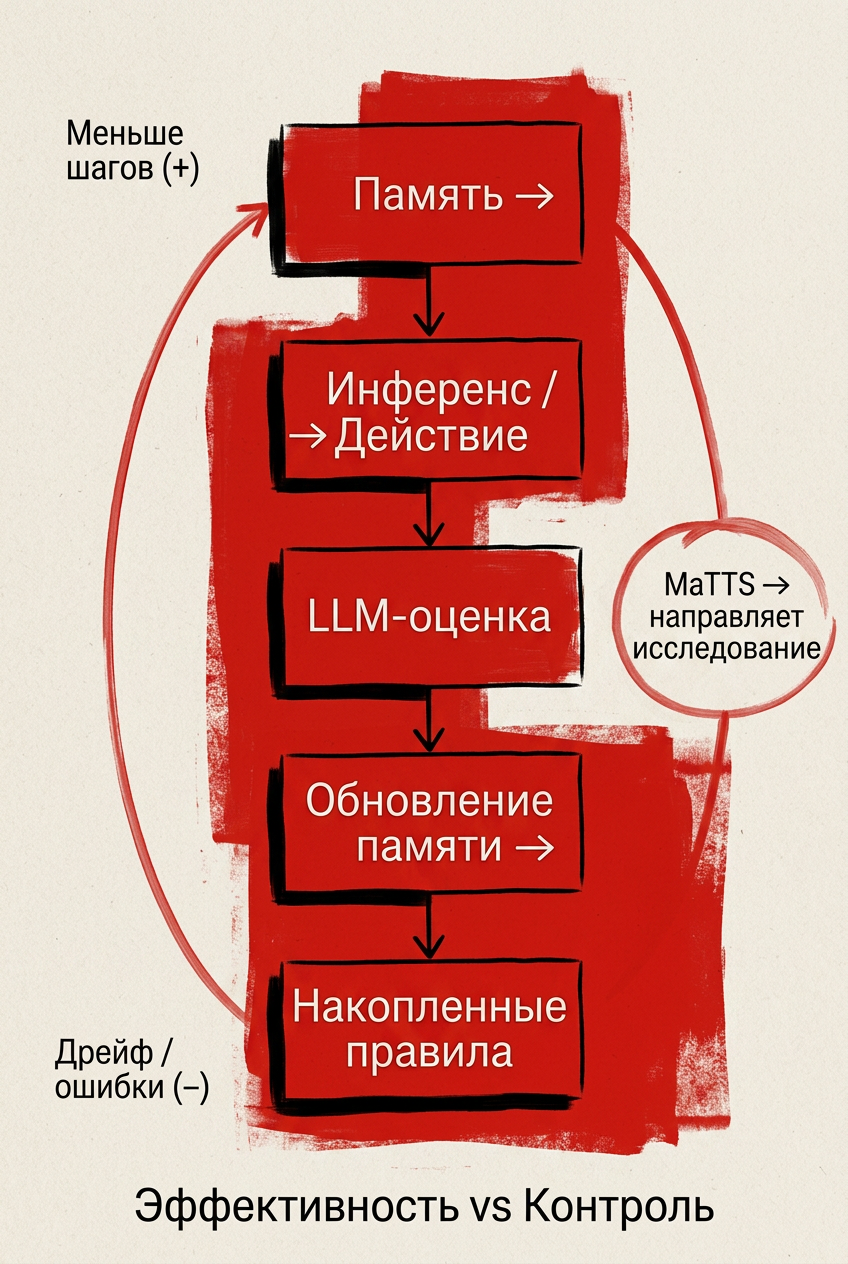
Как работает цикл памяти и где риск
Механика цикла
ReasoningBank извлекает не факты, а стратегии: шаблоны решений и причинные гипотезы. Во время инференса MaTS использует их, чтобы направить поиск.
Цикл простой:
извлечение памяти
действие агента
самооценка через LLM-as-a-judge
запись нового опыта в память
Пример. Агент решает задачу на WebArena:
извлекает правило «избегать длинных цепочек действий»
выбирает короткий путь
LLM оценивает результат как допустимый
правило усиливается и записывается
Если правило было неверным, оно закрепляется и влияет на следующие решения.
Почему цикл усиливает поведение
Память хранит структурированные правила, а не отдельные шаги. LLM‑оценка добавляет мета‑информацию и тоже попадает в память. MaTS направляет исследование по уже подтверждённым путям.
В итоге система усиливает собственные решения. Это повышает повторяемость стратегий.
К чему это приводит
Плюс: меньше шагов и выше скорость.
Минус: ошибки становятся системными. Без памяти агент повторяет их случайно. С памятью — стабильно.
Вывод: память — это управляющий слой. Он меняет динамику обучения и требует контроля.
Где это ломается в продакшене
Улучшение на тестах, сбои на новых данных
Триггер: смена распределения данных. Метрики растут, шагов меньше. Но на новых сценариях агент выбирает старые шаблоны. MaTS ведёт его по знакомым путям. Ошибки появляются на краях распределения.
A/B успешен, но поток деградирует
Триггер: rollout после локального выигрыша. В эксперименте всё лучше baseline. В продакшене одно правило блокирует альтернативы. Агент застревает в одном сценарии. Ошибки идут цепочкой.
Инцидент без бага в коде
Триггер: накопленные «уроки» из прошлых эпизодов. Код и данные чистые, но агент ошибается. Причина — память подталкивает к неверным решениям. Это не видно без анализа памяти.
Во всех случаях проблема одна: память влияет на поведение сильнее контекста.
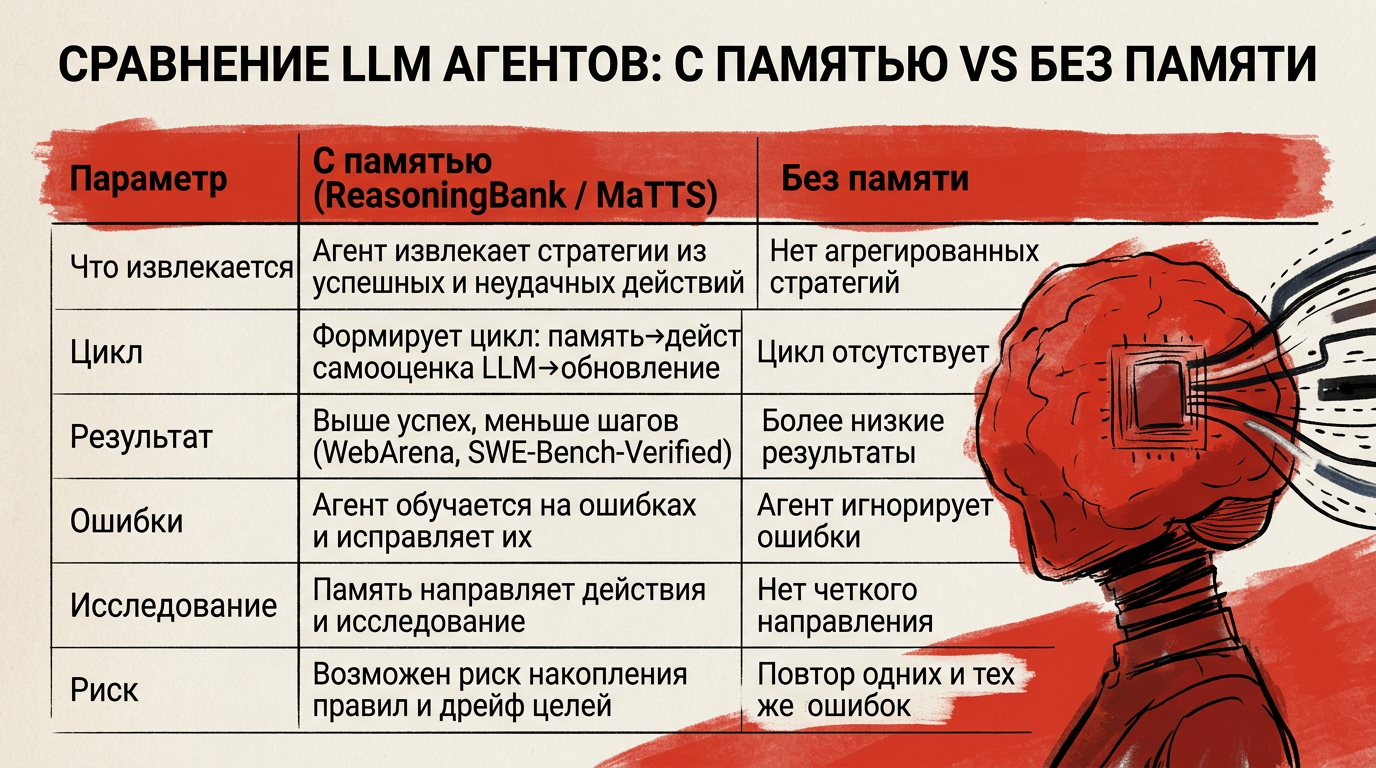
Параметр | Memory-enabled (ReasoningBank / MaTS) | Baseline (без памяти) |
|---|---|---|
Что извлекается | Стратегии рассуждения из успешных и неудачных действий агента | Нет агрегированных стратегий, опора на текущие шаги |
Структура обучения (цикл) | Замкнутый цикл: извлечение памяти → действие → самооценка через LLM → добавление воспоминаний | Отсутствие замкнутого обновляемого хранилища стратегий |
Результат на бенчмарках | Улучшает успешность задач и снижает количество шагов (WebArena, SWE-Bench-Verified, Gemini-2.5-Flash) | Меньшая успешность и больше шагов по сравнению с подходами с памятью |
Отношение к ошибкам | Учитывает ошибки как источник обучения и формирует «предупреждающие уроки» | Ориентирован на успешные траектории, ошибки не агрегируются в правила |
Направление исследования | MaTS использует память для направления исследования во время инференса; память исследование усиливают друга | Исследование не направляется памятью, меньше обратной связи между траекториями |
Риск поведения | Формирование процедурных правил и аккумуляция стратегий, возможен дрейф и закрепление ошибок | Повторение стратегических ошибок без системного закрепления, но меньше риска аккумуляции неправильных правил |
Что это меняет на практике
Память — активный контролёр стратегии. Она ускоряет решения, но формирует правила, которые влияют на выбор путей.
Это ломает привычную логику «метрики выросли — значит лучше». Память может закрепить неудачные эвристики и усилить их через цикл оценки и поиска.
Что делать на практике:
валидировать память как код: тесты на разные сценарии, включая out-of-distribution
логировать изменения памяти: какие правила добавились и почему
отслеживать повторяемость стратегий: рост одинаковых паттернов — сигнал риска
Вывод: выгода есть, но только при контроле. Без него память становится источником скрытых ошибок.
Память в обучении агентов — это не улучшение по умолчанию. Это слой, который управляет поведением и может накапливать ошибки.
ReasoningBank и подобные подходы показывают рост эффективности на бенчмарках. Но замкнутый цикл памяти усиливает не только правильные решения, но и неверные.
Практический минимум контроля:
тестировать память на разных типах задач
логировать и версионировать изменения памяти
уметь быстро откатывать состояние памяти
отслеживать метрики поведения, а не только успеха
Если этого нет, выигрыш в скорости превращается в риск для системы.









