
Автоматизация code review с помощью LLM в разработке: быстрее релизы, дороже контроль
В Avito LLM генерируют около 85% комментариев к pull request, а команда обрабатывает ~1000 PR в неделю. Это заметно ускоряет первый фидбэк (10–60 секунд) и разгружает разработчиков. Но точность около 85% и 32% устаревших замечаний создают издержки на разбор шума.
Автоматизация code review с помощью LLM в разработке работает только при чётком контуре контроля: оркестрация, фильтры и внутреннее размещение модели. Иначе выигрыш по скорости съедается проверкой ложных сигналов.
Для CTO и тимлидов это смена нагрузки, а не её исчезновение. Быстрее time‑to‑market — да. Но больше внимания качеству и метрикам. Дальше — разбор архитектуры и того, какие показатели держать под контролем, чтобы ускорение не превратилось в техдолг.
Где возникает разрыв ожиданий
Идея простая: подключаем LLM к пайплайну — и ревью перестаёт тормозить. Комментарии появляются сразу, рутина уходит, цикл сокращается.
На практике появляется шум. Примеры: модель советует «вынести константу», хотя это уже сделано в следующем коммите; или предлагает изменить формат логирования, не видя соглашений модуля. Такие замечания формально корректны, но в текущем контексте бесполезны.
Это системный эффект. Без фильтров и контроля качества скорость оборачивается дополнительной работой: нужно отсеивать неточные и устаревшие советы.
Итог: вы не получаете «меньше ревьюеров». Вы получаете новый операционный слой и риск роста техдолга. Вопрос уже не «можно ли», а «какие элементы системы обязательны».
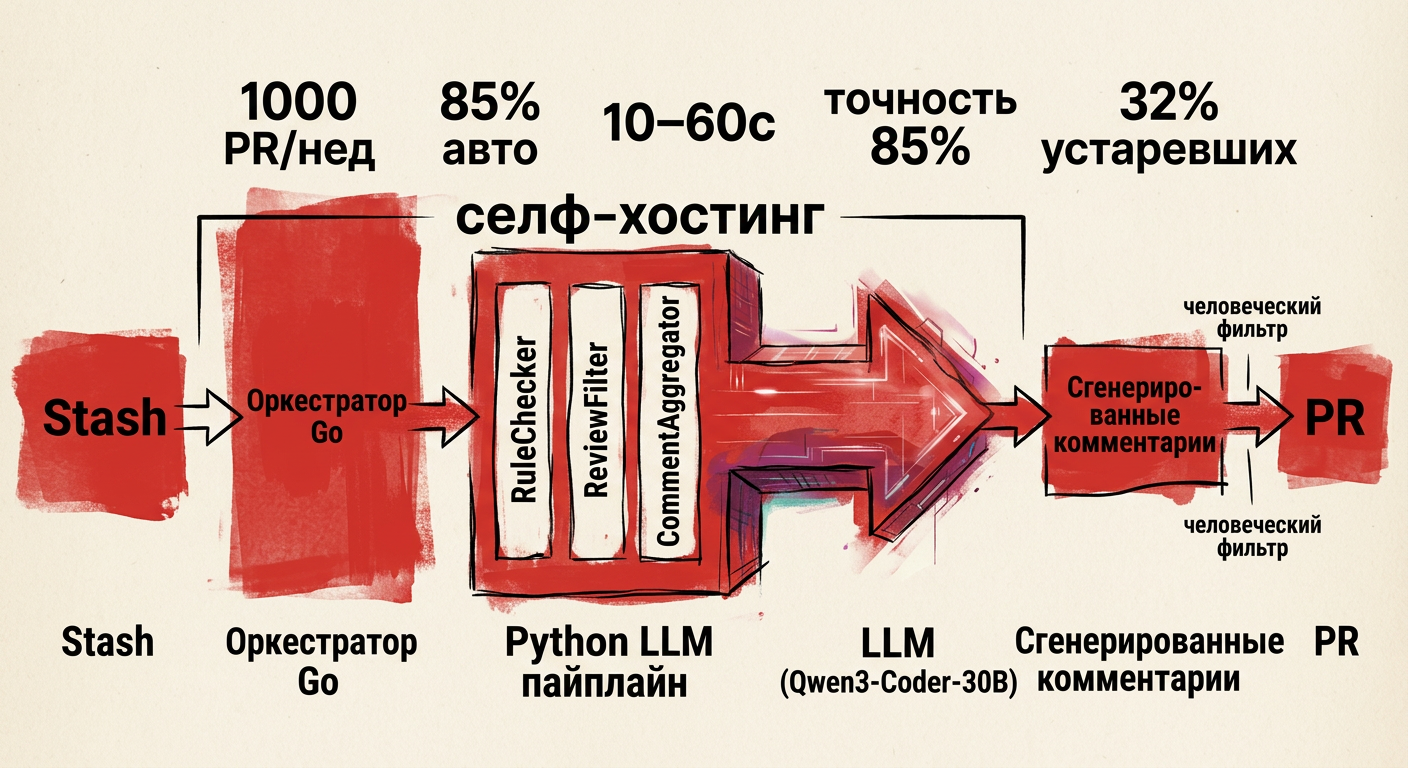
Как устроена система и где контроль
Как это работает
LLM встроена в поток обработки PR. В Avito используется Qwen3‑Coder‑30B внутри инфраструктуры. Дифф приходит из Stash в Go‑оркестратор, дальше его обрабатывает Python‑пайплайн. На выходе — набор комментариев к PR. Около 85% из них создаёт модель; объём — ~1000 PR в неделю.
Что делают компоненты пайплайна
RuleChecker закрывает очевидные правила: стиль, базовые анти‑паттерны, простые проверки диффа. Это дешёвый слой, который снимает часть нагрузки с модели.
ReviewFilter режет шум. Он отбрасывает повторы, слишком общие советы и комментарии без привязки к строкам диффа. Также фильтр может снижать вес рекомендаций, если они противоречат локальным правилам.
CommentAggregator собирает итог: объединяет дубли, группирует по файлам и оставляет только релевантные замечания.
Почему возникают ошибки
Модель быстрая и даёт единый стиль, поэтому первый фидбэк приходит за 10–60 секунд. Но точность около 85% означает неизбежные промахи. Ещё 32% комментариев устаревают из‑за новых коммитов: контекст меняется быстрее, чем живёт совет.
К чему это приводит
Скорость растёт, но появляется новый слой поддержки: нужно следить за точностью, обновлять правила, обеспечивать ресурсы для внутреннего размещения. Для критичных изменений остаётся обязательной проверка человеком.
Ключевой вывод: ценность даёт не модель, а оркестрация — где стоят фильтры, как меряется точность и как отбрасываются устаревшие замечания.

Типовые ситуации в работе
Быстрый комментарий, который быстро устаревает
Комментарий приходит через полминуты. Это ускоряет цикл. Но он основан на текущем диффе и не учитывает следующие коммиты. При доле устаревших замечаний 32% команда тратит время на перепроверку и откаты.
Вывод: воспринимайте автокомментарии как подсказку, а не решение.
Поток комментариев перегружает команду
При ~1000 PR в неделю и 85% автокомментариев возникает задача сортировки. Без фильтрации разработчики тратят часы на разбор ложных срабатываний. Нагрузка не исчезает — она смещается в операции.
Вывод: масштаб делает фильтры обязательными, иначе растут скрытые издержки.
Метрика | Значение | Краткое значение для системы |
|---|---|---|
PR в обработке в неделю | 1000 PR/week | Масштаб, при котором автоматизация становится необходимой |
Доля комментариев от LLM | 85% | Большая часть фидбэка генерируется автоматически |
Время генерации комментария | 10–60 секунд | Быстрый отклик, но комментарий может устареть при доработках |
Точность системы | 85% | Оставляет место для ошибок и требует валидации |
Доля устаревших комментариев | 32% | Значимый риск шумовых/неактуальных замечаний |
Где появляется измеримый эффект
При объёме около 1000 PR в неделю первый фидбэк приходит за 10–60 секунд. Это сокращает время ожидания ответа и разгружает разработчиков на рутинных проверках. При доле автокомментариев ~85% команда быстрее проходит первые итерации ревью.
Но эффект держится только при контроле качества. Связка RuleChecker, ReviewFilter и CommentAggregator снижает долю шума, а человек закрывает критичные изменения.
Практический вывод: ускорение достигается не количеством комментариев, а их релевантностью. Для этого нужны фильтры, внутреннее размещение модели и мониторинг точности.
Что внедрять в первую очередь
Автоматизация не заменяет ревьюера. Она ускоряет цикл и переносит часть работы в систему контроля.
Приоритеты внедрения:
Сначала настройте фильтрацию: RuleChecker и ReviewFilter должны убирать повторы и неактуальные советы.
Затем обеспечьте управляемость: внутреннее размещение модели и метрики (точность, доля устаревших комментариев, время ответа).
Так оркестрация делает процесс предсказуемым: меньше шума, быстрее решения, ниже риск техдолга.
Платформы вроде АСПЕКТ показывают тот же принцип: ИИ‑слой внутри инфраструктуры превращает поток данных в управляемые пайплайны измеримые результаты.









