
Заголовок: Simula генерация синтетических данных через механизм дизайна — почему простая генерация не даёт стабильного качества
Лид: Simula ломает ожидание: синтетические данные — это не «сгенерировать побольше». Без системного mechanism design нельзя получить стабильное качество и переносимость.
Простой пример сбоя. Модель обучили на сгенерированных письмах поддержки. На тестах всё хорошо. В проде появляются реальные жалобы с нестандартными формулировками — модель теряется. Причина — генерация не покрыла вариации и не проверила сложность.
Simula вводит seedless‑подход на уровне датасета и добавляет независимую проверку качества, метрики покрытия и сложности. Это не трюк, а процесс, который проверили на задачах от кибербезопасности до школьной математики и применили в продуктах Google.
Вывод для команд: важна не масса примеров, архитектура генерации и контроль качества. Дальше — где ломаются простые подходы и как Simula делает генерацию управляемой системой.
Почему «больше синтетики» не работает
Синтетические данные часто считают быстрым обходом сбора реального датасета. Генерируешь много примеров, донастраиваешь модель и получаешь приемлемый результат. Объём будто компенсирует неточность.
Simula показывает обратное. Без системного mechanism design качество нестабильно и плохо переносится между задачами. Seedless‑подход с встроенной валидацией и независимыми критиками решает именно эту проблему, а не добавляет «ещё данных».
Отсюда риск: модель выглядит хорошей на одном наборе и ломается в проде или в новом домене. Приоритет смещается — от объёма к архитектуре генерации и контролю качества.
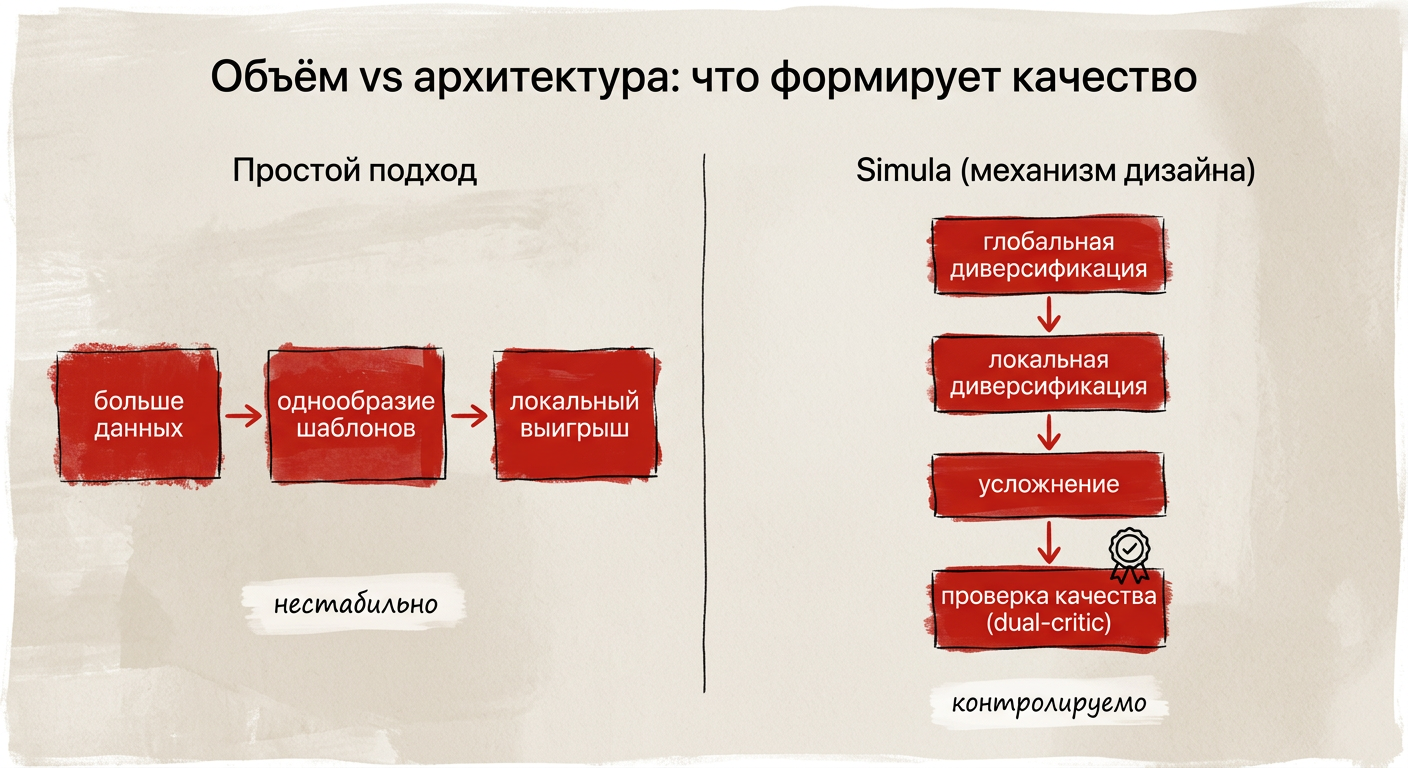
Как устроена генерация в Simula
Как это работает
Simula превращает генерацию в инженерный процесс. Работает не с отдельными примерами, а с датасетом целиком. Есть цикл из четырёх шагов: глобальная диверсификация, локальная диверсификация, усложнение, проверка качества.
Так задаётся «архитектура данных»: какие вариации обязательны, как растёт сложность и что считается корректным примером.
Ключ — встроенная валидация. Используется dual‑critic с независимой оценкой ответов. Один критик проверяет корректность и полноту, второй — устойчивость к перефразированию и крайним случаям. Если ответы расходятся или не проходят порог, пример отклоняется или возвращается на усложнение. В итоге в датасет попадают только согласованные и проверенные случаи.
Почему это работает
Подход seedless — без исходного целевого датасета. Значит, управлять нужно покрытием и сложностью. Для этого вводятся метрики: Taxonomic Coverage и Calibrated Complexity Scoring с Elo‑оценками.
Пример: если класс сценариев недопредставлен, падает покрытие — цикл усиливает глобальную диверсификацию. Если задачи слишком лёгкие, Elo‑оценка сложности не растёт — добавляется усложнение. Метрики дают прямую обратную связь и позволяют сравнивать наборы данных.
Подход проверяли в реальных сценариях: до 512K примеров на домен, пять доменов — кибербезопасность, юридическое мышление, школьная математика и мультиязычные знания. В обучении использовали Gemini 2.5 Flash как teacher и Gemma‑3 4B как student. Это показывает масштаб и применимость.
Суть хорошо выражает цитата: «there is no single "optimal" way to generate data... the relationship between "good" data and downstream performance is deeply idiosyncratic.» Поэтому метрики и критики — обязательны.
К чему это приводит
Объём сам по себе не даёт переноса. Без архитектуры модель учится на локальной пользе данных и ломается при смене условий.
В проде это выглядит как деградация при атаках, переобучение на шаблоны и пробелы в знаниях. Seedless‑подход и критики позволяют строить датасеты там, где реальные данные редки или чувствительны.
Поэтому Simula применяют в продуктах Google: детекция мошенничества в звонках Android и фильтрация спама в Google Messages. Архитектура генерации напрямую влияет на поведение системы.
Что из этого следует
Качество синтетики задаётся архитектурой генерации и валидацией, а не количеством. Значит, генерацию нужно проектировать как систему: с метриками покрытия, контролем сложности и независимыми критиками.
Отсюда следующий шаг — выбор конкретных метрик и встраивание критики в пайплайн.

Где простая генерация даёт сбои
Когда донастройка на синтетике кажется быстрым решением
Нужно быстро дообучить модель — генерируете большой объём примеров. Генерация идёт без требований к покрытию и сложности. Модель подхватывает шаблоны генератора и теряет устойчивость. Вывод: рост объёма усиливает перекосы, если процесс не спроектирован.
Когда локальные тесты создают ложную уверенность
Метрики на сгенерированном тесте выглядят стабильно. Но тренировка и тест используют одинаковые принципы генерации. Модель оптимизируется под стиль генератора, а не под реальность. Вывод: проверка должна быть независимой от генерации.
Когда нет реальных данных и остаётся синтетика
Из‑за приватности переходите на seedless‑генерацию. Сценарии покрыты частично, метрики покрытия и сложности не считаются. Появляются «слепые зоны», хотя датасет кажется полным. Вывод: синтетический датасет — инженерный артефакт с измеримыми свойствами.
Параметр | Значение |
|---|---|
Число этапов процесса генерации (глобальная диверсификация, локальная диверсификация, усложнение, проверка качества) | 4 |
Максимальный объём сгенерированных примеров на один домен | 512000 |
Число доменов, на которых тестировали Simula | 5 |
Число моделей в эксперименте (teacher и student) | 2 |
Упомянутые продуктовые применения Simula в Google | 2 |
Что даёт механизмный дизайн на практике
Синтетика начинает работать, когда есть система. Метрики и независимая проверка убирают иллюзию контроля, которую давал простой рост объёма. Локальные выигрыши перестают маскировать провалы.
Практический эффект. Ошибки отлавливаются на этапе генерации, а не в проде. Итерации короче: метрики сразу показывают, где не хватает покрытия или сложности. Dual‑critic отсеивает слабые примеры до обучения.
В итоге датасет становится воспроизводимым артефактом, а не набором шаблонов. Меньше регрессий после релизов, стабильнее перенос на новые сценарии.
Отсюда следующий вопрос — какие метрики и механизмы контроля внедрять в пайплайн.
Синтетические данные часто используют как быстрый способ увеличить объём. Это даёт локальные улучшения без гарантий переноса и стабильности.
Simula предлагает другой подход: проектировать генерацию как mechanism design. Seedless‑модель и цикл из четырёх шагов — глобальная диверсификация, локальная диверсификация, усложнение, проверка качества — делают датасет воспроизводимым. Dual‑critic и метрики покрытия и сложности превращают качество в измеримую величину.
Это работает, потому что контроль покрытия и калиброванной сложности даёт стабильные сигналы обучения, а независимая валидация не даёт модели подстроиться под генератор. Подход проверен на пяти доменах и объёмах до 512K примеров на домен и уже используется в продуктах Google.
Аналогия на практике: такие системы, как АСПЕКТ, объединяют анализ, валидацию и пайплайны внутри инфраструктуры. Тот же принцип — данные обрабатываются как управляемая система. Это и есть путь к воспроизводимости и надёжности синтетики.









