
Архитектура HTAP в PostgreSQL для масштабируемых корпоративных СУБД — почему AI‑ассистент недостаточен
Компании вкладываются в «AI‑ассистентов» и ждут быстрый эффект. Видно улучшение интерфейса, проще демо, меньше ручной работы. Но деньги появляются не здесь.
Экономика возникает в слое данных: масштабирование, низкие задержки, единая работа транзакций и аналитики. Это и есть архитектура HTAP в PostgreSQL для масштабируемых корпоративных СУБД. Рассмотрим на примере Tantor XData Gen3, представленного 7 апреля в Москве.
Продукт заявляет HTAP, разделение вычислений и хранения, RDMA‑сеть и параллельную обработку на всех узлах. При этом сохраняется совместимость с PostgreSQL и 1С. Это меняет фокус: не «AI сверху», а перестройка ядра данных.
Ставка практическая. От архитектуры зависит TCO и поведение под нагрузкой. Для CTO и CIO важен не модуль генерации, а способность системы расти без сбоев и задержек. Дальше — где упирается классический PostgreSQL и какие решения предлагает HTAP.
Где возникает ложный эффект от AI
Кажется, что достаточно добавить AI‑ассистента — и бизнес ускорится. Интерфейс становится удобнее, отчёты строятся быстрее. Это создаёт ощущение, что ценность наверху.
На деле отдача появляется внизу — в данных. Когда система снимает ограничения масштаба и даёт аналитику рядом с транзакциями, эффект становится устойчивым. Здесь ключ — архитектура HTAP в PostgreSQL для масштабируемых корпоративных СУБД. Tantor XData Gen3 как раз про это.
Если остаться на уровне «ассистентов», проблемы проявятся при росте нагрузки. Увеличатся задержки, вырастет TCO, аналитика начнёт мешать транзакциям. Дальше — что именно ограничивает классический PostgreSQL и как это обходят HTAP‑решения.
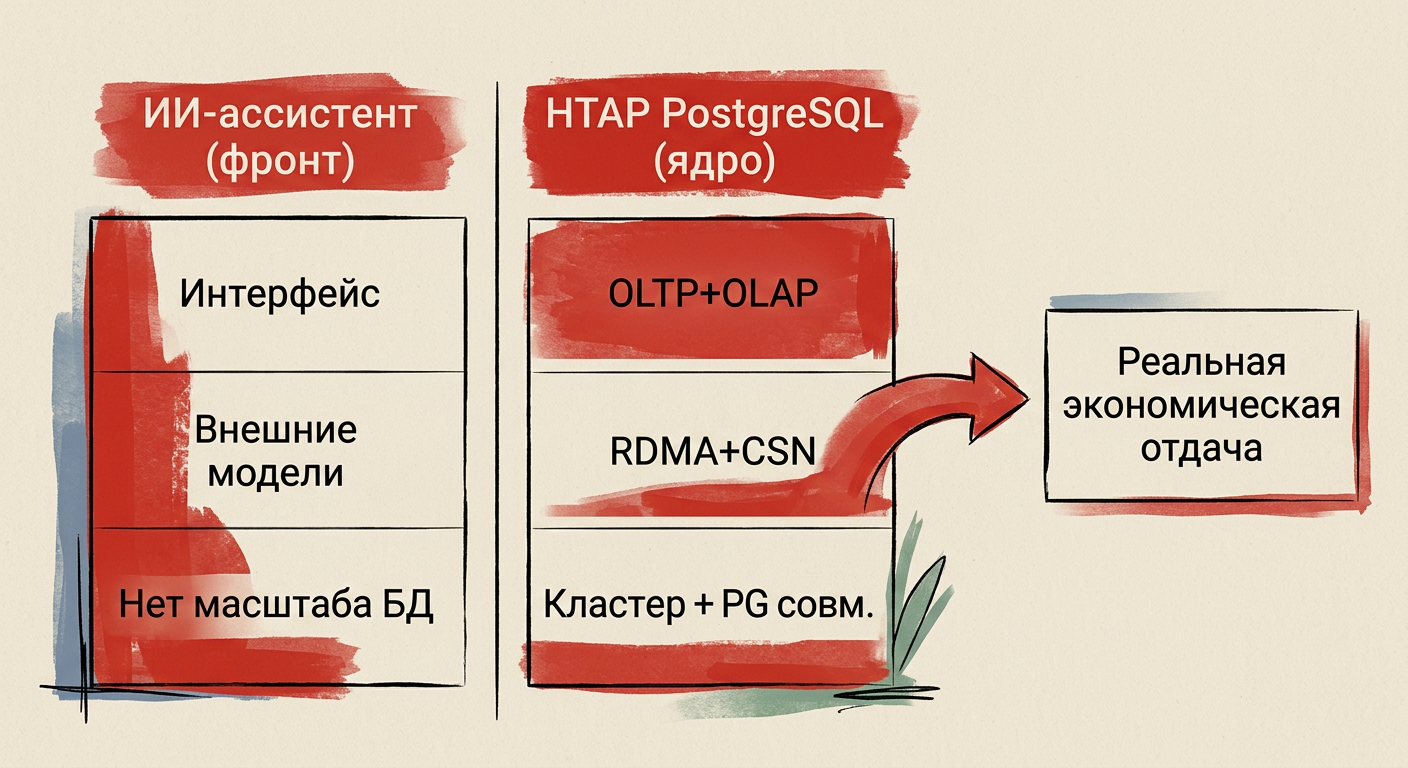
Как устроена HTAP‑архитектура на практике
HTAP объединяет транзакции и аналитику в одной системе. Данные не копируются в отдельное хранилище. OLTP и OLAP выполняются над одной базой с низкой задержкой.
В Tantor XData Gen3 вычисления отделены от хранения. Запросы идут параллельно на всех узлах кластера. Для приложений это по‑прежнему PostgreSQL, но внутри — распределённая модель и многопоточная обработка. Согласованность держится механизмами вроде CSN.
Классический PostgreSQL эффективен на одном сервере. Дальше упирается в CPU и диск. При смешанной нагрузке задержки растут: аналитика и транзакции конкурируют за одни ресурсы. Разделение слоёв снимает это узкое место.
RDMA‑сеть уменьшает задержку обмена между узлами до почти «локальной». Это важно для синхронных транзакций и быстрых аналитических срезов: миллисекунды вместо десятков миллисекунд при сетевых обменах. Параллелизм на узлах даёт рост пропускной способности без переписывания приложений.
Tantor заявляет RDMA и использование AMD EPYC. Это позволяет распараллеливать запросы и удерживать согласованность с меньшими накладными расходами. При этом сохраняется обратная совместимость с PostgreSQL и работа с 1С.
Компромисс очевиден: поднять производительность и масштаб, не меняя поведение для приложений. В систему добавлено около 1,5 млн строк кода — цена за такой скачок.
На уровне отказоустойчивости используется Tantor RAC: один пишущий и несколько читающих узлов. При сбое происходит автоматическое переключение с минимальным простоем.
Итог для бизнеса: меньше конкуренции между OLTP и OLAP, ниже задержки и меньше затрат на интеграцию. Но есть риск внедрения — решение ещё проходит тесты в реальных системах. При позиционировании рядом с Oracle Exadata, SAP HANA и IBM Netezza цена ошибки высока.

Типовые ситуации, где ломается подход «AI сверху»
Когда CFO требует «быстрый» AI для экономии
Команды внедряют чат‑бота и автогенерацию отчётов. Нагрузка растёт. Аналитические запросы начинают делить CPU и диск с транзакциями. Задержки увеличиваются в разы на пиках.
Итог: таймауты и падение пользовательского опыта. Интерфейс работает, процессы — нет. Решение — разнести нагрузки внутри архитектуры, а не улучшать фронт.
Когда продукту нужна аналитика в реальном времени
Появляется цепочка OLTP → ETL → OLAP. Данные для моделей запаздывают на минуты или часы. Каждый отчёт требует синхронизации и преобразований.
Итог: медленные релизы и ошибки согласованности. Стоимость ETL растёт вместе с объёмом. Причина — аналитика вынесена в отдельную систему.
Когда нельзя ломать 1С и текущие приложения
Интеграция с 1С обязательна. Попытки добавить отдельную аналитическую платформу ведут к репликациям и доработкам.
Итог: сроки срываются, TCO растёт. Практичнее решение, которое сохраняет совместимость и масштабирует инфраструктуру.
Решение | HTAP поддержка | Масштабирование за пределы одного сервера | Разделение вычислений и хранения | RDMA‑сеть | Совместимость с PostgreSQL |
|---|---|---|---|---|---|
Классический PostgreSQL | Нет | Ограничено (ограничения масштаба за пределами одного сервера) | Нет | Нет | Да (это сама PostgreSQL) |
Tantor XData Gen3 | Да (заявлено HTAP) | Проектирована для кластерного масштаба (параллельная обработка на всех узлах) | Да (разделение вычислений и хранения) | Да (используется RDMA) | Сохранена обратная совместимость (работает с приложениями PostgreSQL и 1С без изменений) |
AI‑ассистент / фронт над данными | Нет (не архитектурное решение HTAP) | Не решает ограничения СУБД сам по себе (не даёт DB‑масштабирования) | Нет | Нет | Не релевантно (эффект внешний, не на уровне СУБД) |
Как меняется экономика и работа команды
AI‑фронт улучшает интерфейс, но не убирает узкие места СУБД. Перестройка архитектуры меняет экономику.
В Tantor XData Gen3 нагрузка уходит с одного сервера на кластер. Разделение вычислений и хранения и параллельная обработка снижают конкуренцию между OLTP и OLAP. Механизмы CSN и Tantor RAC уменьшают блокировки и простой.
Это влияет на расходы. Меньше интеграций — ниже OPEX на поддержку ETL и синхронизаций. Масштабирование добавлением узлов снижает риск крупных CAPEX на «большой сервер». Команды тратят меньше времени на обходные решения и больше — на продукт.
Практический вывод: перенос фокуса с «ассистентов» на слой данных даёт предсказуемую отдачу и ускоряет разработку без переписывания приложений.
Как выбрать: критерии для CTO и CIO
Узкое место — не интерфейсы, а СУБД. AI‑ассистент не снимает ограничения классического PostgreSQL при росте нагрузки.
Решение — менять ядро. Архитектура HTAP в PostgreSQL для масштабируемых корпоративных СУБД объединяет OLTP и OLAP без постоянной репликации. Приёмы — разделение вычислений и хранения, RDMA, CSN и схема RAC — дают параллелизм и сохраняют совместимость с PostgreSQL и 1С.
Проверка перед выбором:
есть ли рост задержек при смешанной нагрузке;
упираетесь ли в один сервер при масштабировании;
растёт ли стоимость ETL и синхронизаций;
нужна ли совместимость без переписывания приложений.
Если ответы «да», приоритет — инфраструктура данных. Подход Tantor XData Gen3 делает ставку на это и прямо влияет на TCO и устойчивость под пиками.
Платформы уровня АСПЕКТ показывают, как AI‑слой работает поверх данных внутри инфраструктуры. Но эффект появляется только там, где ядро уже способно выдержать нагрузку.









