
Уровни зрелости описания данных для внедрения LLM — почему каталог и глоссарий не спасают
LLM уже дают ценность. Но в крупных компаниях их ответы часто ошибочны и медленны. Причина — не модель, а данные вокруг неё.
Моя позиция проста: зрелость метаданных — это не документы. Это производственная система, от которой зависит работа LLM. Если метаданные остаются ручными и разрозненными, точность и безопасность не достигаются.
Дальше — конкретная шкала зрелости из четырёх уровней: от ручного хаоса к автоматизированному каталогу и формализованному семантическому слою.
Ставка высокая. В компаниях есть сотни тысяч таблиц. Новые появляются быстрее, чем их описывают. Один отчёт может использовать более 100 источников. Штрафы за утечки доходят до 3% выручки.
Практика показывает: без семантического слоя text-to-sql остаётся ненадёжным. С ним точность растёт примерно на 20% и может превышать 90%.
Этот материал для CDAO и лидеров данных. Разберём уровни зрелости и покажем, какие компоненты превращают метаданные в рабочую систему.
Почему каталог и глоссарий не решают задачу
Ожидание простое: собрать каталог, заполнить глоссарий и настроить промпты. Кажется, что этого достаточно.
Но в реальности данные устроены иначе. Есть сотни тысяч таблиц. Новые появляются постоянно. Один отчёт может опираться на более 100 источников.
В таких условиях каталог без автоматизации и семантики не работает. Модель получает разрозненный контекст и отвечает с ошибками.
Это не проблема LLM. Это отсутствие рабочего уровня метаданных.
Отсюда последствия: инвестиции не окупаются, ответы приходят медленно, риски утечек остаются.
Выбор простой. Либо метаданные остаются документами. Либо становятся системой.

4 уровня зрелости метаданных для LLM
Уровень 1. Ручной хаос
Данные растут быстрее, чем их описывают. Таблиц сотни тысяч. Связи фиксируются в головах или локальных файлах.
LLM видит отдельные куски. Метрики и связи не определены.
Результат — случайные ответы и высокая ошибка.
Уровень 2. Каталог без полноты
Появляется каталог и глоссарий. Но физическая модель не подтягивается автоматически.
Без коннекторов вроде DataHub или OpenMetadata каталог остаётся неполным.
LLM получает частичный контекст. Ошибки сохраняются.
Уровень 3. Формализованный семантический слой
Метрики, фильтры и связи описаны явно. Часто через YAML.
Модель опирается не на слова, а на согласованную логику.
По данным Snowflake, точность text-to-sql растёт примерно на 20%.
Уровень 4. Автоматизированная система метаданных
Физическая модель загружается автоматически. Связи извлекаются, например, из SQL-логов.
Разметка чувствительных данных происходит через метаданные. Доступ можно ограничивать без работы самими данными.
ИИ помогает находить владельцев, но назначение остаётся ручным.
На этом уровне можно стремиться к точности SQL выше 90%.
Почему компании застревают
Рост данных быстрее ручной работы. Связи между источниками не фиксируются. Один отчёт может использовать 100+ источников.
В итоге LLM получает противоречивый контекст.
Вывод
Переход между уровнями — это не про документы. Это про архитектуру: автоматический каталог + семантический слой + разметка.
Без этого LLM остаётся нестабильным инструментом.
Где ошибки проявляются на практике
Когда SQL выглядит правильно, но цифры неверные
Запрос простой: «выручка по регионам». LLM генерирует SQL.
Но цифры не совпадают с дашбордами.
Причина — разные определения выручки. Где-то брутто, где-то чистая.
Модель не знает, какую использовать.
Результат — ручная проверка и потеря времени.
Когда связи есть, но ответственности нет
ИИ строит lineage и предлагает владельцев.
Но никто не подтверждает ответственность.
Связи есть, управления нет.
Риски и задержки остаются.
Когда KPI противоречат другу
Два отчёта дают разные значения.
Оба используют много источников.
Метрики и фильтры заданы по-разному.
Нет единой семантики.
Результат — ручные разборы и задержка решений.
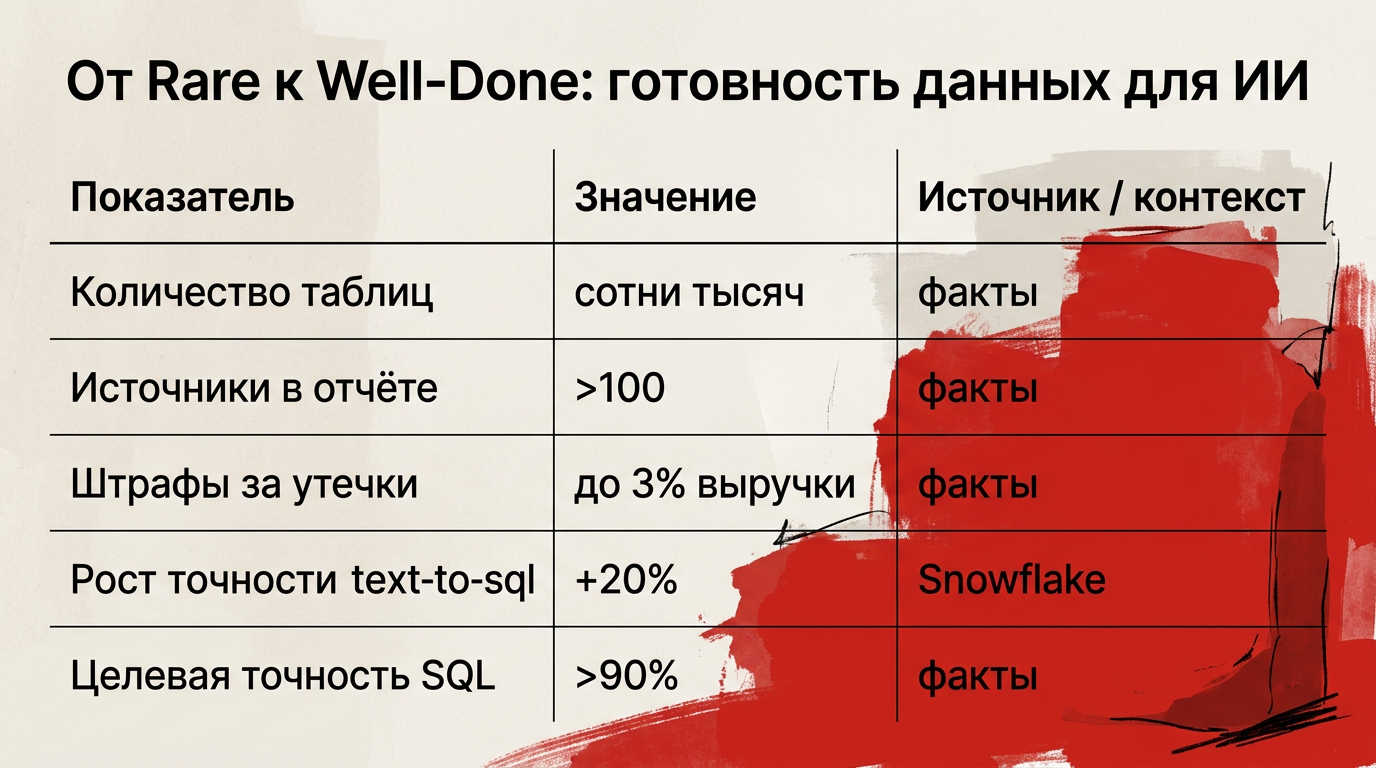
Показатель | Значение | Источник / контекст |
|---|---|---|
Количество таблиц в крупных организациях | сотни тысяч таблиц | ARTICLE_FACTS |
Число источников в одном аналитическом отчёте | более 100 источников | ARTICLE_FACTS |
Возможные штрафы за утечки персональных данных | до 3% годовой выручки | ARTICLE_FACTS |
Улучшение точности text-to-sql при наличии семантического слоя | ≈ +20% (в среднем) | Snowflake, ARTICLE_FACTS |
Целевая точность генерации SQL семантическим слоем | более 90% | ARTICLE_FACTS |
Что даёт переход на зрелые метаданные
Проблема не в удобстве. Это источник ошибок.
При сотнях тысяч таблиц ручной подход не масштабируется. Отчёты на 100+ источников ломают согласованность.
Семантический слой даёт модели чёткие определения. Это сразу повышает точность. По Snowflake — примерно на 20%.
Практический эффект:
меньше ручной проверки отчётов
быстрее ответы на запросы
Каталог без автоматизации не решает задачу. Он остаётся справочником.
ИИ может ускорить поиск связей, но не заменяет ответственность и логику метрик.
Вывод: только архитектурный переход даёт результат — автоматический каталог, семантика и разметка.
Если свести всё к модели зрелости, картина простая.
1 уровень — хаос: данные есть, системы нет. 2 уровень — каталог: видимость структуры без полноты. 3 уровень — семантика: появляются согласованные метрики. 4 уровень — автоматизация: система начинает работать как производство.
Только на последних двух уровнях LLM дают стабильный результат.
Поэтому главный вывод: уровни зрелости описания данных для внедрения LLM — это не теория, а практическое условие.
Без этого LLM остаётся экспериментом. С этим — становится рабочим инструментом.









