
Архитектура AI-ассистента для управленческих решений под давлением: single‑shot LLM против мультиагентов — кто выдержит дедлайн
Хакатон длился 8 часов. Нужно было решить 4 бизнес‑проблемы и подготовить рекомендации для совета директоров с горизонтом 14 дней.
Интуитивно тянет к мультиагентной схеме: разделить задачи, поставить агентов, настроить оркестрацию. Но практика показала обратное. Single‑shot LLM с динамическим контекстом дал быстрый и устойчивый результат без долгой отладки.
Для C‑level и техлидов это не теория. Под давлением важны скорость ответа, предсказуемость и простота эксплуатации. Ниже — где именно мультиагенты ломаются и почему single‑shot оказывается практичнее.
Почему мультиагенты тормозят под дедлайном
На старте решение кажется очевидным: распараллелить работу и дать каждому агенту свою роль. Это обещает модульность и точность.
В нашем кейсе это не сработало. За 8 часов нужно было покрыть 4 задачи. Оркестрация около 10 агентов потребовала времени на маршрутизацию данных, согласование контекста и отладку интерфейсов. Контекст «расползался», ответы становились непоследовательными.
Single‑shot LLM с динамическим контекстом отвечал за 2–4 секунды. На один ход — один вызов модели. Меньше интеграции, меньше сбоев, предсказуемый результат.
В итоге ресурсы ушли не в решения, а в починку архитектуры. Дальше — системные причины этого эффекта.
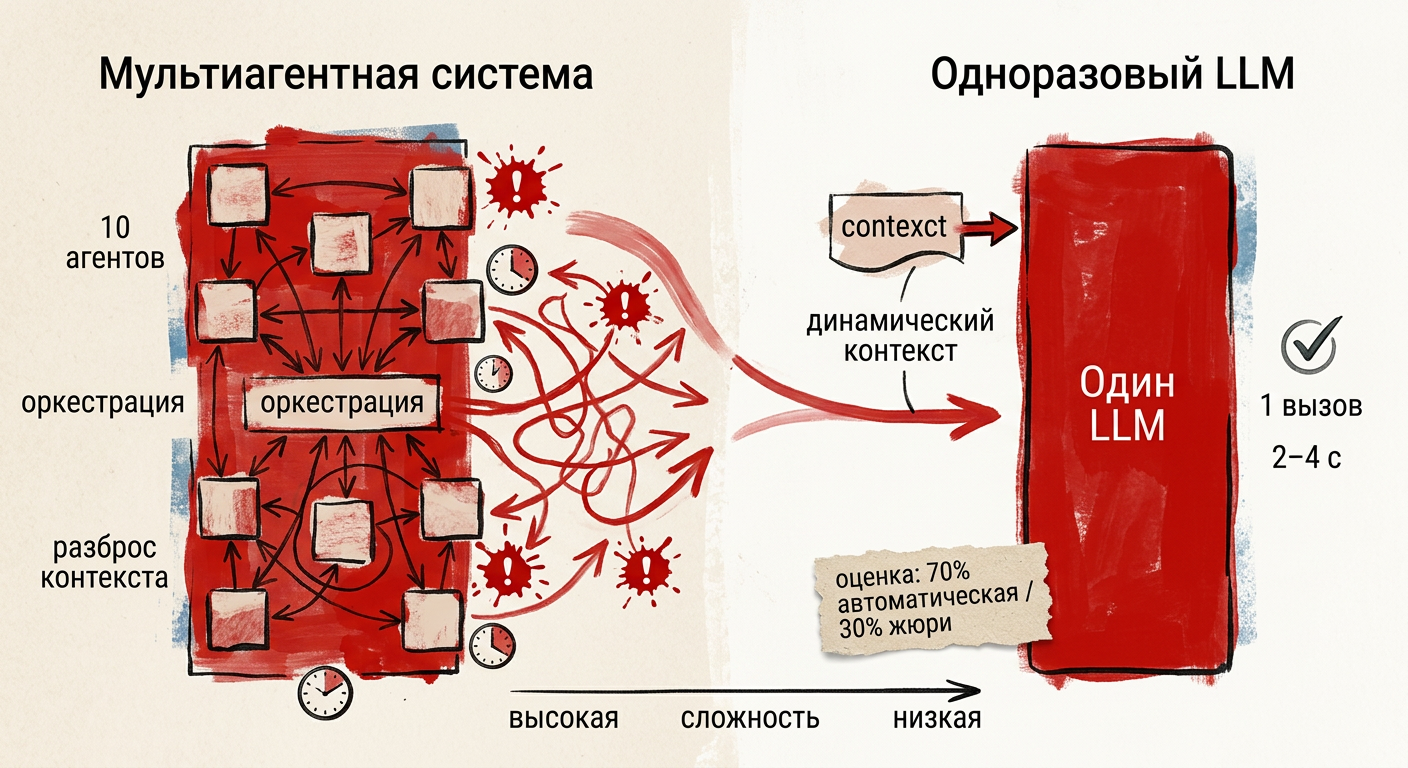
Как устроен single‑shot и где ломаются мультиагенты
Как это работает
Single‑shot собирает весь входной контекст и делает один вызов LLM. В кейсе использовалась Claude Sonnet. Ответ — за 2–4 секунды. Состояние между агентами не хранится. Оркестрации нет: один запрос → одно решение.
Это снижает задержку (latency) и убирает цепочки зависимостей. Меньше точек отказа — ниже риск ошибок на стыках.
Почему мультиагенты проседают
При ~10 агентах растёт время интеграции и число интерфейсов. Появляются три узких места:
синхронизация контекста между агентами;
маршрутизация данных;
отладка взаимодействий.
В условиях 8 часов это критично. Каждая несогласованность увеличивает error rate и время цикла правок. Команда фиксирует не бизнес‑логику, а связки между агентами. Не случайно участники назвали это оверинжинирингом.
Что даёт один вызов
Один LLM‑вызов на ход фиксирует поведение системы. Латентность стабильна, трассировка проста, воспроизводимость выше. Динамический контекст (RAG, агрегация релевантных фрагментов) даёт модели нужные данные без разбиения на агентов.
Инфраструктура Cloud.ru и виртуальные машины Evolution обеспечили ровную пропускную способность. Это убрало внешние колебания и усилило предсказуемость.
К чему это приводит
Для руководства меняются приоритеты. Важнее не максимальная «умность», а управляемость под срок. Мультиагенты увеличивают время внедрения и стоимость отладки. Также падает воспроизводимость при изменении данных.
В системе оценки (70% автоматика, 30% жюри) выигрывают стабильность и скорость. Это напрямую влияет на баллы за управленческие решения.
Критерии выбора
Когда брать single‑shot:
жёсткий дедлайн (часы или дни);
несколько задач сразу (в нашем случае 4);
требуется воспроизводимость для автоматической оценки;
ограниченные ресурсы на интеграцию.
Когда мультиагенты уместны:
длинные процессы без жёсткого срока;
сложная декомпозиция, где нужна изоляция ролей;
есть время настройку и мониторинг связей.
Что в итоге
Под давлением архитектурная достаточность важнее предельной сложности. Single‑shot снижает интеграционные риски и удерживает качество ответа.
Три сценарии, где разница видна сразу
Один дедлайн и четыре направления
Роль: продуктовый директор. Срок — 14 дней, внутри прототип за 8 часов. План с 10 агентами увеличивает время на согласование контекста. Растёт latency ответа и число правок. Итог — разрозненная презентация и ручные доработки.
Single‑shot даёт цельный ответ за 2–4 секунды. Ниже вариативность — меньше правок перед показом.
Команда делает «красивую» модульность
Роль: техлид. Много агентов, чёткие роли. На практике растёт время интеграции и каскад ошибок: сбой одного агента ломает цепочку. Увеличивается время релиза.
Один вызов с прозрачным контекстом сокращает цикл: быстрее получить рабочий результат и перейти к проверке гипотез.
Оценка автоматикой и жюри
Роль: команда продукта. 70% — автоматика, 30% — жюри. Мультиагенты дают разброс ответов и сложную трассировку. Падает воспроизводимость — риск просадки автоматической части.
Single‑shot даёт стабильные ответы и понятную проверку. Это снижает риск на автоматической оценке.
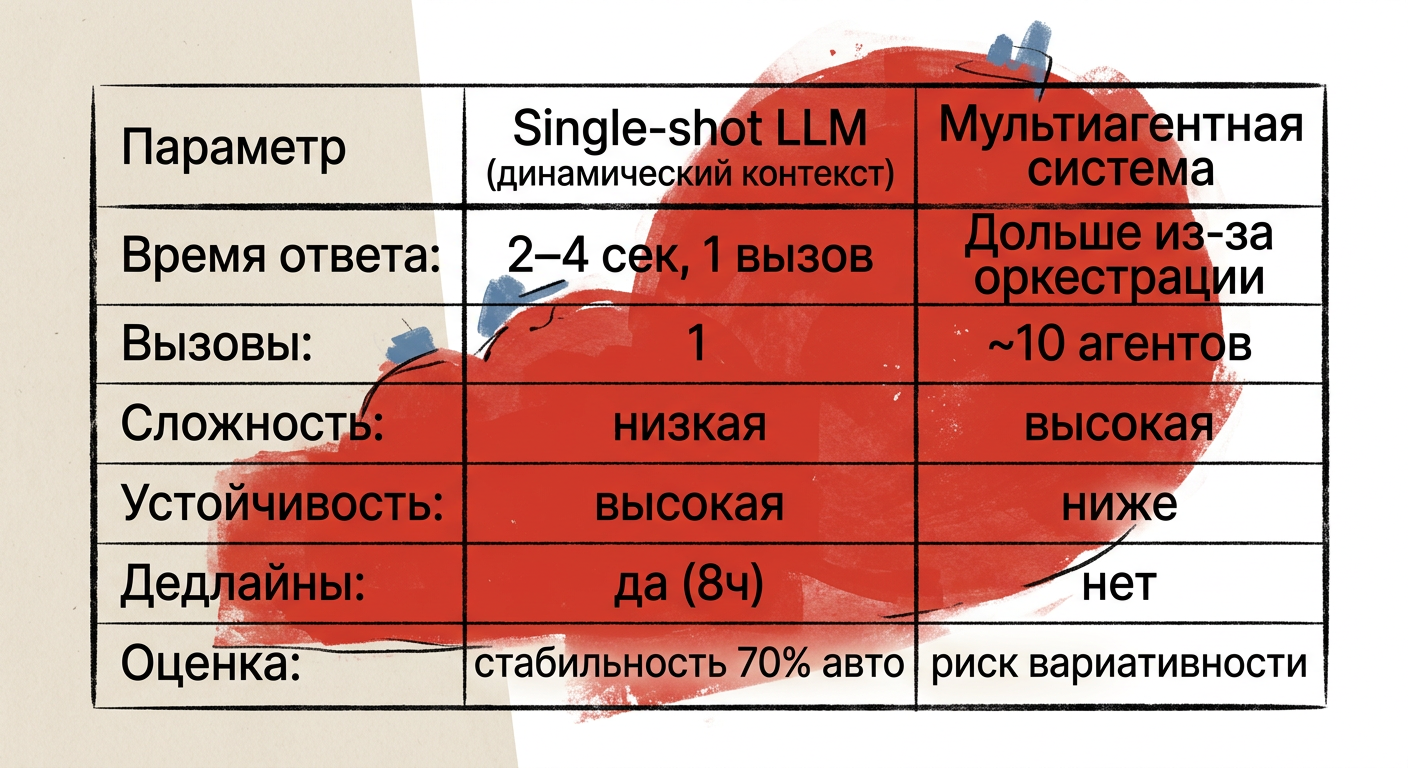
Параметр | Single-shot LLM (динамический контекст) | Мультиагентная система |
|---|---|---|
Время ответа | 2–4 секунды, один LLM‑вызов на ход | Увеличивается из‑за оркестрации и отладки |
Количество LLM‑вызов на ход | 1 (фиксировано) | Несколько — в примере ~10 агентов |
Сложность настройки | Низкая — «не требует множества усилий для отладки сценария» | Высокая — «создание мультиагентной системы оказалось задачей более сложной» |
Устойчивость под давлением | Высокая — меньше точек отказа, предсказуемость | Ниже — согласованность контекста ломается, больше точек отказа |
Подходит для коротких дедлайнов | Да — применимо в хакатоне (8 часов) | Нет — интеграция съедает время |
Влияние на автоматическую оценку | Положительное — скорость и стабильность поддерживают автоматическую часть (70%) | Риск вариативности и непоследовательности, снижение воспроизводимости |
Что это даёт на практике
Под жёсткий срок модульность начинает мешать. В хакатоне (8 часов) время уходило на связки, а не на выводы.
Single‑shot даёт быстрый цикл: 2–4 секунды на ответ и один вызов на ход. Меньше согласований — меньше задержек и сбоев.
Практический эффект — сокращение time‑to‑decision. Команда быстрее формирует позицию и успевает проверить её перед защитой. Также снижается стоимость разработки: меньше кода интеграции и меньше часов на отладку.
Вывод: при ограниченном времени выигрывает простая, управляемая схема.
Коротко: что делать
Если у вас часы или дни на результат и несколько задач сразу, не стройте сложную оркестрацию.
Возьмите single‑shot LLM с динамическим контекстом: один вызов на ход, ответы за 2–4 секунды, понятная трассировка. Это даёт стабильность для автоматической оценки (70% автоматика / 30% жюри) и ускоряет подготовку материалов для совета директоров.
Дальше масштабируйте не количеством агентов, а качеством контекста: сбор источников, RAG, аккуратные саммари.
Платформы вроде АСПЕКТ помогают это сделать: превращают документы, аудио и видео в структурированные материалы, дают чат с опорой на источники и разворачиваются внутри инфраструктуры компании.
Итог: под давлением выигрывает архитектурная достаточность single‑shot.









